High Availability Services¶
The Application Server is deployed as a cluster. Within the cluster are the AS nodes that are always active. The NIU is the load balancer and overall cluster monitor. The NIU can be partnered to provide high availability (HA) services with one designated primary NIU and one designated secondary NIU that is an exact replication of the primary NIU.
This configuration allows the NIUs to share state and improves the availability of services by allowing for failover.
Network Configuration¶
The mechanism by which HA services are provided is the use of shared virtual IP (VIP) addresses. In an HA pair configuration, the NIUs share a common external HA IP address that is used by incoming calls. One of the NIUs is online while the other is offline, acting as a standby, and is ready to take over should the online NIU experience a failure. The defined HA IP address is aliased on the external IP interface of the online NIU. To allow for either NIU to assume the HA alias, the external IP interface of both NIUs should interface to a common switch.
In an HA pair, the state of the SIP stack is shared between the two NIUs. On the public IP addresses, event messages are sent to the offline NIU when there is a state change so that it is always ready to assume traffic.
At startup, the NIUs automatically attempt to detect each other. If one NIU cannot be detected, the other NIU goes online and assumes the HA IP address. If detection does occur successfully, then the NIU that is assigned the role of primary in the cluster_config.xml file goes online and assumes the HA IP address.
The cluster_config.xml file defines the following attributes on the NIU:
- primary-node-ip-address
The IP address of the designated primary NIU.
- partner-search-timeout
The length of time (in milliseconds) to wait for a heartbeat message from a partner NIU during the startup sequence before going online.
- network-device
The interface that is connected to the service network.
- heartbeat-device
The interface that is connected to the dedicated network for the partner NIU and is used for exchanging heartbeat messages.
- ping-interval
The length of time (in milliseconds) between successive ping requests. Network connectivity is tested by periodically sending ping requests to the IP addresses specified in the ping-address element.
- ping-wait
The length of time (in milliseconds) to wait for a response to a ping request before declaring that the specified ping address is unreachable.
- heartbeat-interval
The length of time (in milliseconds) to wait between successive heartbeat messages before detecting there may be an issue. The default value is 1000.
- heartbeat-deadcount
The number of sequential unanswered heartbeat messages allowed before the partner NIU is considered down. The default value is 4.
- heartbeat-port
The port to use for sending and receiving heartbeat messages.
- arp-interval
The length of time (in milliseconds) between gratuitous ARP messages that are sent from the online NIU for the IP addresses specified in the virtual-ip element.
- secondary-node-ip-address
The IP address of the designated secondary NIU.
Note
For Application Server versions earlier than 4.5.34, the IP addressing used on these networks is constrained. Only the primary NIU IP address can be configured, and the secondary NIU IP address is automatically computed to be the next consecutive address in the subnet.
- primary-heartbeat-address
The heartbeat interface address to be used by the primary NIU.
- secondary-heartbeat-address
The heartbeat interface address to be used by the secondary NIU.
When NIUs in an HA pair are connected to multiple different subnets, it is possible for them to have multiple VIP addresses. For example, in a network where signaling and media are kept on separate networks, there would be a VIP address on the signaling network and another VIP address on the media network.
In this configuration, the connectivity of both networks must be independently tested. The testing is executed by having a set of ping addresses defined for each network and using the group attribute as a symbolic name for the network with which the address is associated.
The <ping-address> element specifies a list of network addresses that are periodically sent ping requests to test network connectivity.
Important
It is recommended to have multiple ping addresses configured. At a minimum, there should be a ping address for an AS at every physical site and for the common external HA IP address.
- group
This optional attribute specifies the symbolic name for the network with which this IP address is associated. This attribute should only be provided if multiple <virtual-ip> tags are used to provide this server with multiple VIP addresses that reside on different networks.
- if-name
This optional attribute specifies the name of the interface on the server which should be used for sending ping requests. This attribute should only be provided if the server has multiple VIP addresses on different subnets.
The <virtual-ip> element specifies a list of VIP addresses that are activated on the server when the NIU is the online member of the HA pair.
- ip-address
This attribute specifies the VIP address that is activated in the online NIU.
- netmask
This attribute specifies the netmask associated with the ip-address.
- broadcast
This attribute specifies the broadcast address associated with the ip-address.
- if-name
This attribute specifies the name of the interface on which this ip-address should be activated.
- is-public-addr
This attribute indicates whether this is the ip-address to which the cluster-aware processes bind. Accepted values are 1 for public or 0 for not public.
For more information about configuration files and attributes, see Configuration or Sample Configuration Files.
Heartbeat Link
Through a private, dedicated IP address, there is an Ethernet link shared by the NIUs known as the heartbeat link. This link should be considered as a crossover cable directly connecting the two NIUs over an independent, separate network and is used to monitor and communicate status between the NIUs of the HA pair when other network links may be unavailable.
This network should be shared only by the partnered NIUs and is isolated, making it not accessible from outside of the HA pair. The reliability of the heartbeat link directly affects the reliability of the HA pair. If the heartbeat link is lost, this will trigger the offline NIU to test if a failover is required. The offline NIU will begin pinging the VIP and will go online if there is no response from the VIP.
As described, HA pair configuration requires a network architecture like that shown in the following diagram:
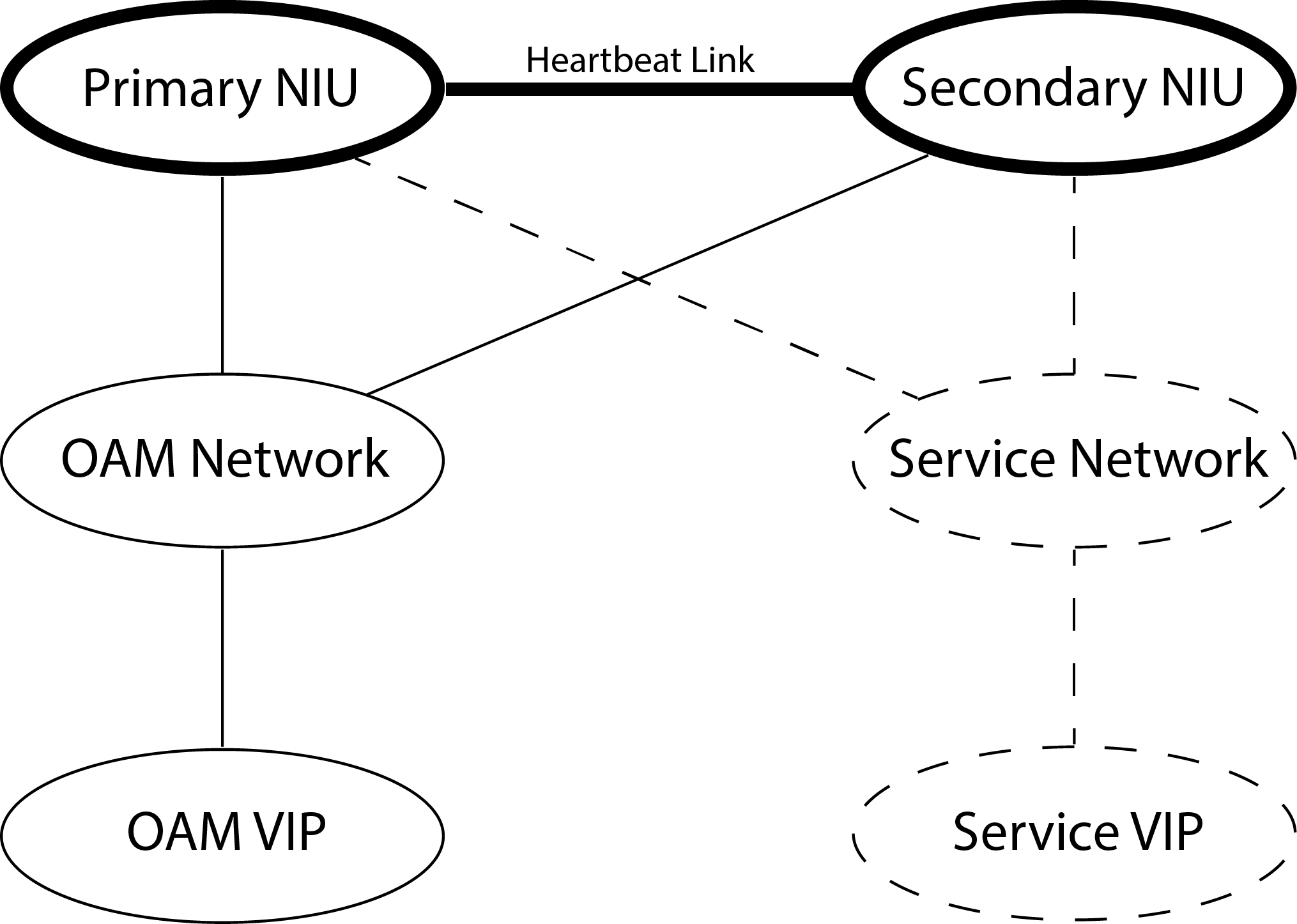
Though not strictly necessary in the case of the heartbeat link, the HA pair for all networks should have Layer 2 adjacency, as the IP address takeover uses Address Resolution Protocol (ARP) to affect the change in location of the VIP. Also, intermediate network elements can reduce the reliability of the HA pair and should be avoided when possible.
Failovers¶
When a failure occurs on the online NIU, a failover automatically directs all incoming traffic to the NIU on standby. A cluster manager process runs on the NIUs to monitor the external HA IP address that is defined in the group attribute of the <ping-address> element. If, at any time, all of the defined IP addresses do not respond, the entire network is declared as being down.
The following situations can cause a failover:
Loss of a critical process on the online NIU
Any critical process, as defined in the ps_master_config.xml file, that cannot be successfully restarted will bring the online NIU down and a message will be sent to the standby NIU to go online.
Loss of the heartbeat link
The heartbeat link is the dedicated network connection between the partnered NIUs. When this method of status communication is lost, the standby NIU will begin pinging the VIP and potentially initiate a failover.
Loss of network
When the network connectivity is lost but the heartbeat link remains, the online NIU will initiate a failover to the standby NIU if the standby network status is up.
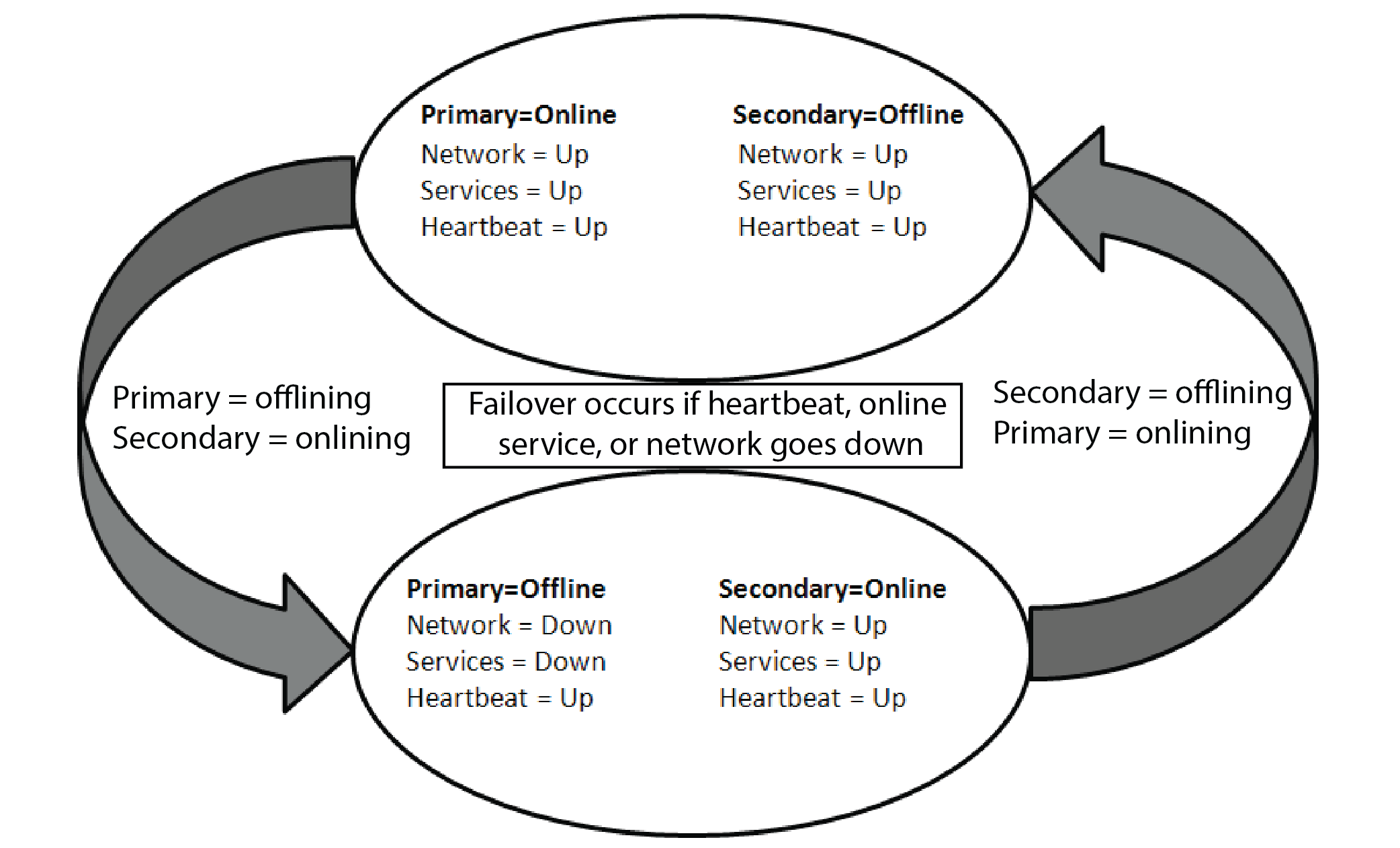
The following diagram shows the transitions between online and offline NIUs in an HA pair configuration. A failover will be prevented from occurring unless the standby NIU is ready to act as the active NIU, as determined during the offlining and onling states shown in the diagram.
Note
If the heartbeat link goes down between the NIUs, the offline NIU attempts to ping the HA IP address. This ping result is used to determine the state of the partner NIU.
Note
If no external HA IP addresses are defined in the group attribute of the <ping-address> element, the external pings always pass and result in a determination that the network is always up, ultimately diminishing the reliability of the HA pair.
Note
There is no automatic recovery to the primary NIU if it becomes available again and the secondary NIU is active.
During a failover, the ps_init process stops all processes that do not run while an NIU is offline and notifies the remaining running processes that the previously online NIU is now offline.
Processes have a control-queue attribute that the ps_init process uses to communicate with each process. For cluster-aware processes, the notify-cluster-changes attribute is enabled, and additional control messages are sent when the NIU state changes. Cluster-aware processes will have the run-offline attribute enabled, meaning that the process will run even when the NIU is in the offline state.
Non-cluster-aware processes can also have run-offline enabled but will not be notified when the NIU state changes. The processes with notify-cluster-changes enabled are started with a set of command line arguments indicating the current state of the NIU when the process is started. Processes can have the start-before-cluster attribute enabled, indicating that they will be started immediately before the clustering state leaves initialization and will be invoked with a status of “initializing” rather than “online” or “offline”.
The following is a list of processes and their configuration in an HA pair environment:
The ps_httpd process is cluster-aware and will bind to the local or primary VIP address with the following configuration:
<process>
name="ps_httpd"
control-queue="ps_httpd"
wait-to-start="10"
restart="1"
critical="1"
run-offline="1"
notify-cluster-changes="1"
</process>
The ps_c_adaptor process is non-cluster-aware and should have the following configuration so that notifications of NIU state changes can be done by the calls to the increment_snmp_event function that it contains:
<process>
name="ps_c_adaptor"
control-queue="ps_c_adaptor"
run-offline="1"
start-before-cluster="1"
restart="1"
critical="1"
</process>
Note
This configuration is not required to receive traps for NIU state changes because the traps are directly implemented in the ps_init process.
The pt_snmp_agent process is non-cluster-aware and should have the following configuration so that traps can be sent from the node immediately on startup and during cluster initialization:
<process>
name="pt_snmp_agent"
control-queue="pt_snmp_agent"
run-offline="1"
start-before-cluster="1"
restart="1"
</process>
The ps_eventdispatcher process is cluster-aware and should have the following configuration:
<process>
name="ps_eventdispatcher"
control-queue="ps_eventdispatcher"
wait-to-start="10"
run-offline="1"
notify-cluster-events="1"
</process>
The ps_appexec, ps_sip_agent, and ps_sip_rs processes are non-cluster-aware.
Processes that do not have a control-queue attribute configured can have a stop-script enabled to be told to either gracefully stop or normally stop. If none is provided, a SIGTERM signal will be sent to the process to ask it to stop gracefully. Additionally, if a process has the notify-cluster-changes attribute enabled, the online-script and offline-script are required, which are called during the cluster transition. Script execution is bound by the script-timeout attribute of the process.
For more information about process configuration, see Configuration.
Monitoring and Managing a Cluster¶
The ps_hastatus and ps_haswitch utilities can be used to monitor and manage a cluster by conveying the following statuses:
The online/offline status of each NIU
The health of the heartbeat link and the partner status that it communicates
The health of the network as determined by ICMP Echo Request messages
To determine overall network status, the ps_init process generates ICMP Echo Request messages, configured by the ping-host attribute, and expects to receive responses. When it fails to receive a response, the network will be marked down on the online NIU. This is generally expected to be configured to the next-hop gateway or logically adjacent systems to the HA pair, allowing detection of network failures that would prevent the active NIU from providing service. This should not be configured to an AS, as failure of a single AS should not trigger a failover, or to any NIU where a failover to the partner NIU would not affect the ability to provide service.
On startup, the ps_init process will wait the specified partner-search-timeout, which has a default value of 10 seconds, to receive information via the heartbeat link about the partner’s status. If this timeout is reached, the NIU will go into an active state.
Description of the ps_hastatus utility¶
The ps_hastatus utility displays the current status of the cluster on both the online NIU and the standby NIU in addition to the time and reason for the most recent cluster transition event. If the heartbeat link is down or the cluster software is not running on the standby NIU, then the partner is shown as operating in an unknown state.
The following is an example of output during normal, healthy operation:
[root@pcs-adas=06] logs # ps_hastatus
***************************************************************************
Local node status:
Services: Online
Cluster: Running
Network: Up
Heartbeat: Up
Private network address: 10.10.105.3
Private heartbeat address: 1.1.0.3
***************************************************************************
Partner node status:
Services: Offline
Cluster: Running
Network: Up
Heartbeat: Up
Private network address: 10.10.105.4
Private heartbeat address: 1.1.0.4
***************************************************************************
Cluster status:
Virtual ip address: 10.10.105.5
Last cluster event: User requested failover
Occurred at: Wed Jan 5 08:13:39 2013 (4 minutes, 44 seconds ago)
Current time: Wed Jan 5 08:18:23 2013
The following is an example of output when the partner is down:
[root@pcs-adas=06] logs # ps_hastatus
***************************************************************************
Local node status:
Services: Online
Cluster: Running
Network: Up
Heartbeat: Up
Private network address: 10.10.105.3
Private heartbeat address: 1.1.0.3
***************************************************************************
Partner node status:
Unknown
***************************************************************************
Cluster status:
Virtual ip address: 10.10.105.5
Last cluster event: User requested failover
Occurred at: Wed Jan 5 08:13:39 2013 (4 minutes, 44 seconds ago)
Current time: Wed Jan 5 08:18:23 2013
The following is an example of output when the partner is transitioning:
[root@imswkx-niu1n ~]# ps_hastatus
Reading default config
***************************************************************
Local node status:
Services: Online
Network: cluster::networking::up
Heartbeat: cluster::heartbeat::up
Private network address: 10.187.197.157
Private heartbeat address: 10.187.197.157
***************************************************************
Partner node status:
Services: cluster::state::offlining
Network: cluster::networking::up
Heartbeat: cluster::heartbeat::up
Private network address: 10.187.197.156
Private heartbeat address: 10.187.197.156
***************************************************************
Cluster status:
Current time: Wed Jun 23 06:47:23 2021
The following is an example of output when no cluster is configured:
[root@pcs-adas=06] logs # ps_hastatus
Cluster is not running on local node.
Description of the ps_haswitch utility¶
The ps_haswitch utility forces a complete switchover from the online NIU to the standby NIU. If the cluster is operating on a degraded NIU, then the output generates a message to the user that a failover is not possible. This utility can automatically determine which NIU is currently active, so no command line arguments are required.
The following is an example of output during normal, healthy operation:
[root@pcs-adas=06] logs # ps_haswitch
Services are running on the local node. Are you sure that you want to switch them
to the remote node? (y/n): y
The following is an example of output when the partner is down:
[root@pcs-adas=06] logs # ps_haswitch
Services are running on the local node. Are you sure that you want to switch them
to the local node? (y/n): y
The following is an example of output when no cluster is configured:
[root@pcs-adas=06] logs # ps_haswitch
Cluster is not running on local node.